🤖Automating the boring stuff: How I obtained the titles of all articles on my blog
In this article, I talk about how I automated the generation of an all-article list with the help of python programming language.


Hi! My name is Narendra Vardi, and I write about my learnings, observations and trends in the Software world. Besides software, I also talk about photography, travel stories, books and movies. If that's something that interests you, consider subscribing.
I follow a lot of bloggers, and on their websites, most of them have an all-article list. It's a place on the website where the user can see all article titles on the website in the form of bullet points.
I love that idea, and I wanted to maintain a similar page. But it needed some coding. After tweaking for a couple of hours, the page is live. Check out the articles-list page now.
In this article, I talk about how I automated the generation of an all-article list with the help of python programming language.
The format of the articles list looks like below:

To create the list, I would need the following:
- Links to all articles are present on my website.
- Title of each article
Here's some dummy skeleton code for the same.
# Dummy skeleton code.
def get_all_post_links():
url_links = []
# do the processing and get the append the links to `url_links`
return url_links
def get_title_from_url_link(url):
title = None
# do the processing and set `title` field.
return title
if __name__ == '__main__':
all_links = get_all_post_links()
for link in all_links:
# Printing as a markdown link.
print('* [{}]({})'.format(get_title_from_url_link(link), link))Now to populate the two methods, I can follow two approaches.
Approach #1: Using APIs provided by Ghost Pro (which I use for hosting my website)
This is the easiest one. Tweaking out some API responses from Ghost Content API Documentation would have been good enough.
To test API responses, I tried to create API Key. I was utterly disappointed that this API key generation capability was unavailable for my account plan. I need to upgrade my account to a different premium plan to support that feature.
Because of this, I was left with only Approach #2, web scraping.
Approach #2: Do some Web Scraping on my very own blog.
Initially, I thought of web scraping by visiting the home page of my account, which is https://www.narendravardi.com. But before that, I researched about the technical aspects of blogs and web scraping. During this research, I learnt about sitemaps.
Sitemaps
According to Google Search Central:
A sitemap is a file where you provide information about the pages, videos, and other files on your site, and the relationships between them. Search engines like Google read this file to crawl your site more efficiently. A sitemap tells Google which pages and files you think are important in your site, and also provides valuable information about these files. For example, when the page was last updated and any alternate language versions of the page.
The sitemap for my blog is an XML file available at the following location: https://www.narendravardi.com/sitemap.xml
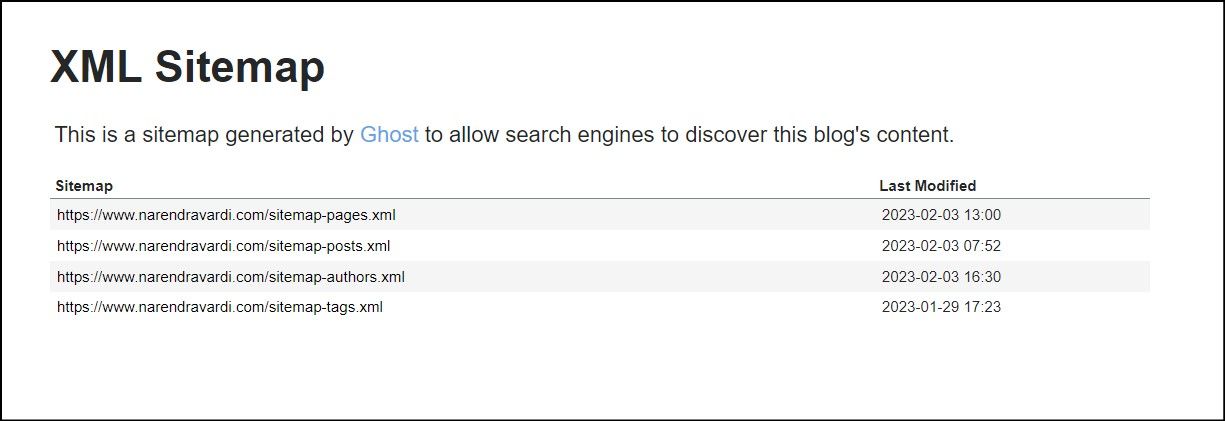
This root sitemap has separate XML mappings for pages, posts, authors and tags.
Fetching all post links
Since we need to get the links of posts, we can visit the sitemap only for sitemap-posts.
If we inspect the source of sitemap-posts, we will know that it's an XML file. Since it's an XML file, we can use python to extract the post links from that XML file.
Now we can make the following changes to the get_all_post_links function:
- Accept the URL path for sitemap-posts.
- Get the XML
- Parse XML
- Append the links to
url_links.
import requests
from bs4 import BeautifulSoup # read about how to parse XML file! :)
ghost_sitemap_posts_url = 'https://www.narendravardi.com/sitemap-posts.xml'
def get_all_post_links(sitemap_posts_url):
# 2. Get the XML
xml_data = requests.get(sitemap_posts_url).content
# 3. Parse XML
soup = BeautifulSoup(xml_data, 'xml')
url_sets = soup.find_all('loc')
url_links = []
# 4. Append the links
for url_set in url_sets:
url_set_text = url_set.text
# site-posts also consists of image links. Ignoring them.
if not 'image' in url_set_text:
url_links.append(url_set_text)
return url_links
def get_title_from_url_link(url):
title = None
# do the processing and set `title` field.
return title
if __name__ == '__main__':
# 1. Accept the URL path for sitemap-posts.
all_links = get_all_post_links(ghost_sitemap_posts_url)
for link in all_links:
print('* [{}]({})'.format(get_title_from_url_link(link), link))Getting the title from the article link
Now it's time to get the title from each post. This involves the following steps.
- Get the HTML page of the post.
- Extract the title of the page and
- Return the title.
import requests
from bs4 import BeautifulSoup # read about how to parse XML file! :)
ghost_sitemap_posts_url = 'https://www.narendravardi.com/sitemap-posts.xml'
def get_all_post_links(sitemap_posts_url):
# 2. Get the XML
xml_data = requests.get(sitemap_posts_url).content
# 3. Parse XML
soup = BeautifulSoup(xml_data, 'xml')
url_sets = soup.find_all('loc')
url_links = []
# 4. Append the links
for url_set in url_sets:
url_set_text = url_set.text
# site-posts also consists of image links. Ignoring them.
if not 'image' in url_set_text:
url_links.append(url_set_text)
return url_links
def get_title_from_url_link(url):
# 1. Get the HTML page of the post.
reqs = requests.get(url)
# 2. Extract the title of the page and
soup = BeautifulSoup(reqs.text, 'html.parser')
# 3. Return the title.
for title in soup.find_all('title'): # why use a for loop for title?
return title.get_text()
if __name__ == '__main__':
# 1. Accept the URL path for sitemap-posts.
all_links = get_all_post_links(ghost_sitemap_posts_url)
for link in all_links:
print('* [{}]({})'.format(get_title_from_url_link(link), link))The output of the script looks as follows:
* [📷Minimalist photographs of farm fields](https://www.narendravardi.com/farm-patterns/)
* [✍️Finding the Nth highest salary from an SQL table](https://www.narendravardi.com/nth-salary/)
* [🎙️Solo Trip to Europe: Podcast interview](https://www.narendravardi.com/soloeurotrip-interview/)I can directly paste the above output into Ghost using the markdown feature.
Don't forget to visit the All Articles page.
That's all for today! :)
Share this article
Copy and share this article: https://www.narendravardi.com/list-automation
Recommendations
If you liked this article, you might also like reading the following.
- Future Software Engineers, read this article before and during your placements.
- The magician who creates digital images from the text: DALL-E
- 🚌Bus Factor in the IT World
❤️ Enjoyed this article?
Forward to a friend and let them know where they can subscribe (hint: it's here).
Anything else? Comment below to say hello, or drop an email!